WWDC18 What’s New in LLVM

前言
LLVM 作为 Apple 御用的编译基础设施其重要性不言而喻,Apple 从未停止对 LLVM 的维护和更新,并且几乎在每年的 WWDC 中都有专门的 Session 来针对 LLVM 的新特性做介绍和讲解,刚刚过去的 WWDC18 也不例外。
WWDC18 Session 409 What’s New in LLVM 中 Apple 的工程师们又为我们介绍了 LLVM 最新的特性,这篇文章将会结合 WWDC18 Session 409 给出的 官方演示文稿 分享一下 LLVM 的新特性并谈谈笔者自己个人对这些特性的拙见。
Note: 本文不会对官方演示文稿做逐字逐句的翻译工作,亦不会去过多介绍 LLVM 的基本常识。
索引
- ARC 更新
- Xcode 10 新增诊断
- Clang 静态分析
- 增加安全性
- 新指令集扩展
- 总结
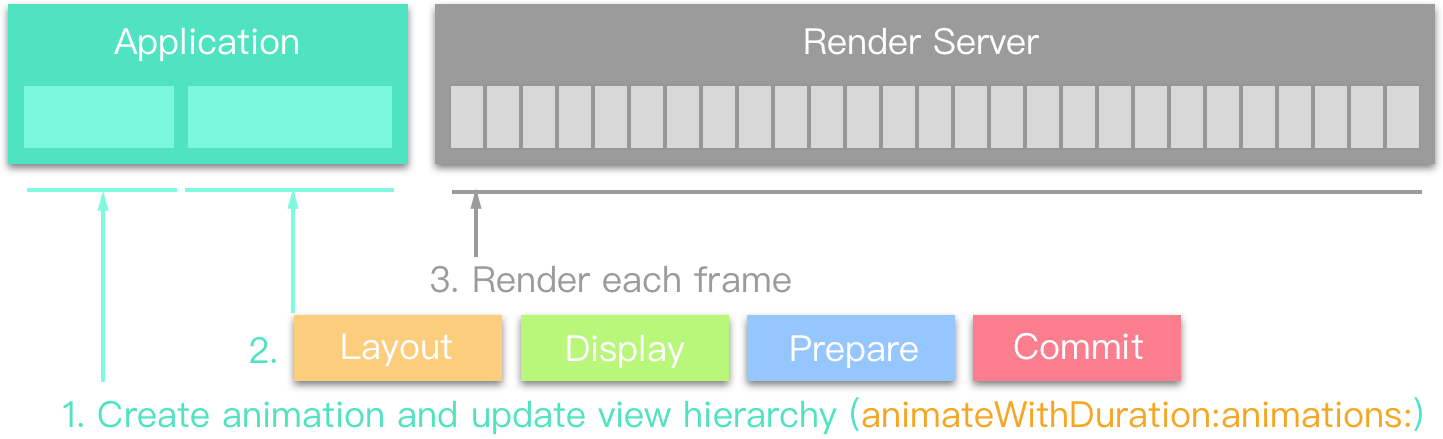
ARC 更新
本次 ARC 更新的亮点在于 C struct 中允许使用 ARC Objective-C 对象。
在之前版本的 Xcode 中尝试在 C struct 的定义中使用 Obj—C 对象,编译器会抛出 Error: ARC forbids Objective-C objects in struct,如下图所示:

嘛~ 这是因为之前 LLVM 不支持,如果在 Xcode 10 中书写同样的代码则不会有任何 Warning 与 Error:

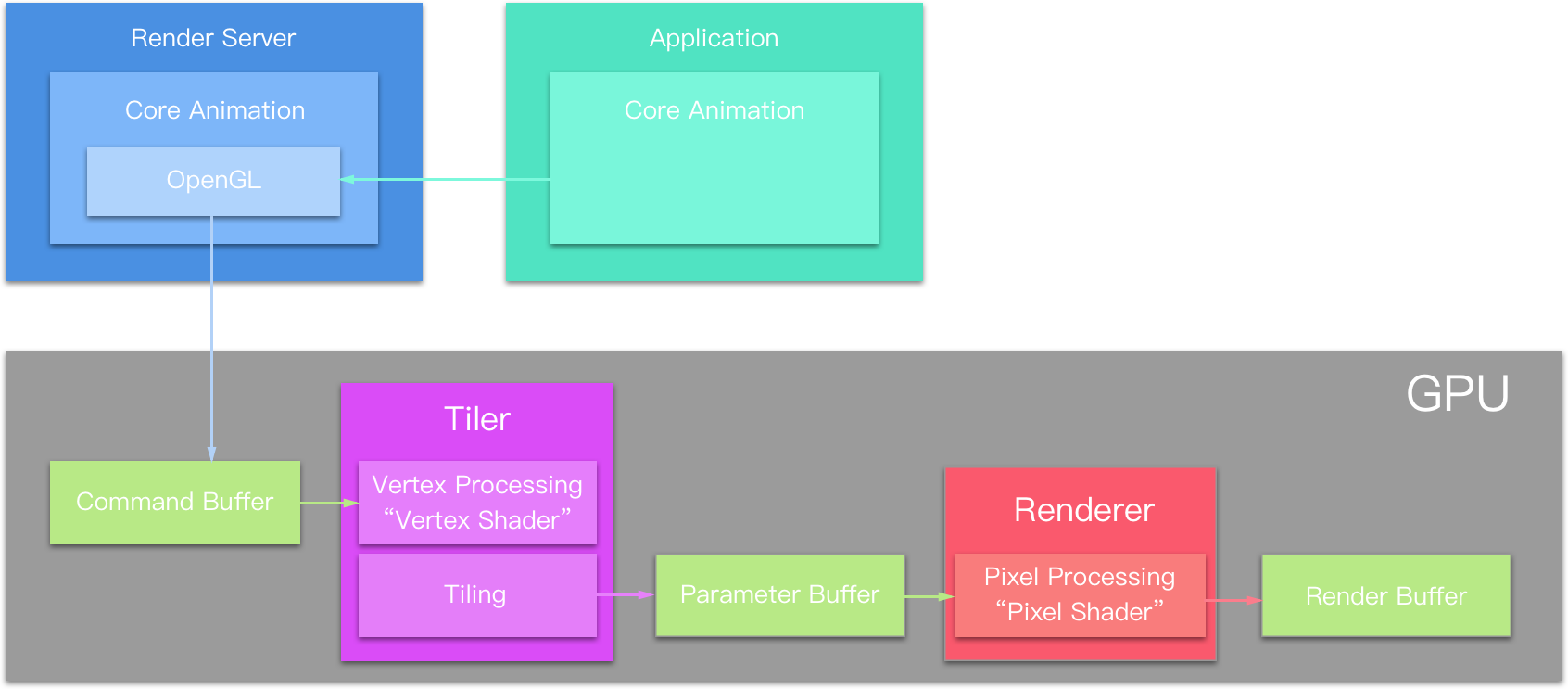
那么直接在 C struct 中使用 Objective-C 对象的话难道就没有内存上的问题吗?Objective-C 所占用的内存空间是何时被销毁的呢?
1 | // ARC Object Pointers in C Structs! |
如上述代码所示,编译器会在 C struct MenuItem 创建后 retain 其中的 ARC Objective-C 对象,并在 orderMenuItem(item); 语句之后,即其他使用 MenuItem item 的函数调用结束之后 release 掉相关 ARC Objective-C 对象。
思考,在动态内存管理时,ARC Objective-C 对象的内存管理会有什么不同呢?
Note: 动态内存管理(Dynamic Memory Management),指非
int a[100];或MenuItem item = {name, [NSNumber numberWithInt:0]};这种在决定了使用哪一存储结构之后,就自动决定了作用域和存储时期的代码,这种代码必须服从预先制定的内存管理规则。
我们知道 C 语言中如果想要灵活的创建一个动态大小的数组需要自己手动开辟、管理、释放相关的内存,示例:
1 | void foo() { |
那么 C struct 中 ARC Objective-C 的动态内存管理是否应该这么写呢?
1 | // Structs with ARC Fields Need Care for Dynamic Memory Management |
答案是否定的!
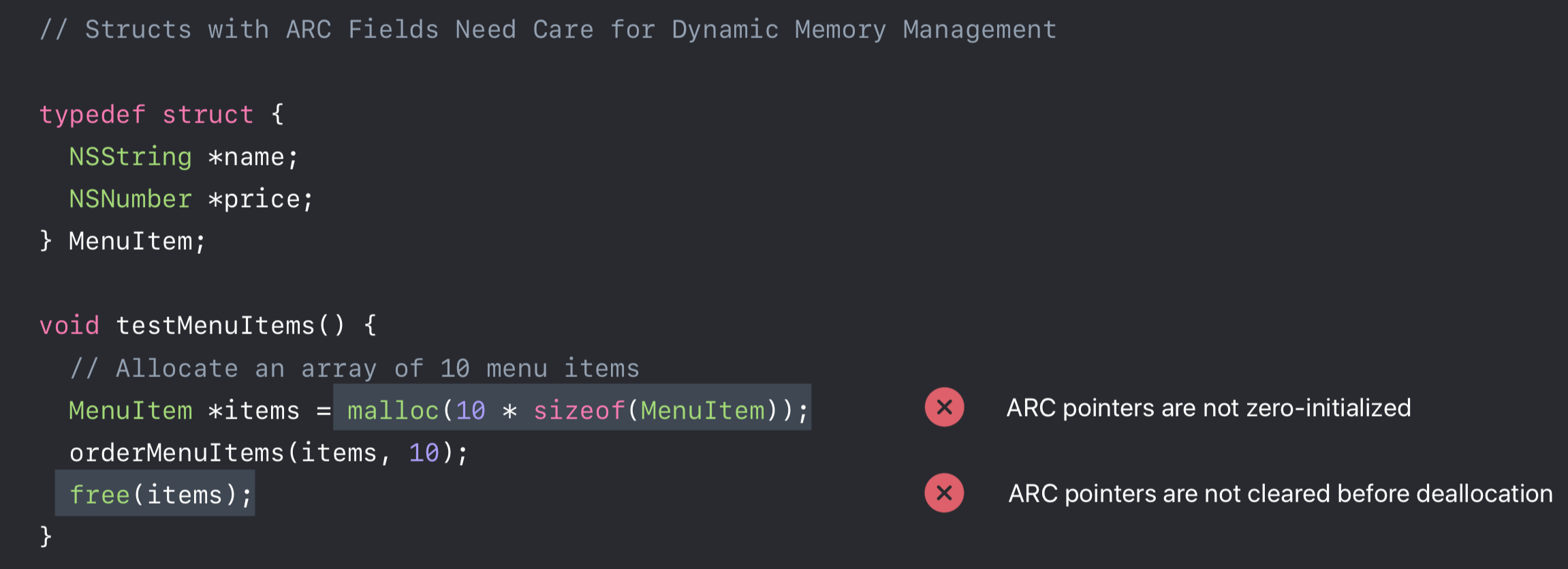
可以看到通过 malloc 开辟内存初始化带有 ARC Objective-C 的 C struct 中 ARC Objective-C 指针不会 zero-initialized。
嘛~ 这个时候自然而然的会想起使用 calloc ^_^
Note:
calloc和malloc均可完成内存分配,不同之处在于calloc会将分配过来的内存块中全部位置都置 0(然而要注意,在某些硬件系统中,浮点值 0 不是全部位为 0 来表示的)。
另一个问题就是 free(items); 语句执行之前,ARC Objective-C 并没有被清理。
Emmmmm… 官方推荐的写法是在 free(items); 之前将 items 内的所有 struct 中使用到的 ARC Objective-C 指针手动职位 nil …
所以在动态内存管理时,上面的代码应该这么写:
1 | // Structs with ARC Fields Need Care for Dynamic Memory Management |
瞬间有种日了狗的感觉有木有?
个人观点
嘛~ 在 C struct 中增加对 ARC Objective-C 对象字段的支持意味着我们今后 Objective-C 可以构建跨语言模式的交互操作。
Note: 官方声明为了统一 ARC 与 manual retain/release (MRR) 下部分 function 按值传递、返回 struct 对 Objective-C++ ABI 做出了些许调整。
值得一提的是 Swift 并不支持这一特性(2333~ 谁说 Objective-C 的更新都是为了迎合 Swift 的变化)。
Xcode 10 新增诊断
Swift 与 Objective-C 互通性
我们都知道 Swift 与 Objective-C 具有一定程度的互通性,即 Swift 与 Objective-C 可以混编,在混编时 Xcode 生成一个头文件将 Swift 可以转化为 Objective-C 的部分接口暴露出来。
不过由于 Swift 与 Objective-C 的兼容性导致用 Swift 实现的部分代码无法转换给 Objective-C 使用。
近些年来 LLVM 一致都在尝试让这两种语言可以更好的互通(这也就是上文中提到 Objective-C 的更新都是为了迎合 Swift 说法的由来),本次 LLVM 支持将 Swift 中的闭包(Closures)导入 Objective-C。
1 | @objc protocol Executor { |
1 |
|
Note: 在 Swift 中闭包默认都是非逃逸闭包(non-escaping closures),即闭包不应该在函数返回之后执行。
Objective-C 中与 Swift 闭包对应的就是 Block 了,但是 Objective-C 中的 Block 并没有诸如 Swift 中逃逸与否的限制,那么我们这样将 Swift 的非逃逸闭包转为 Objective-C 中无限制的 Block 岂不是会有问题?

别担心,转换过来的闭包(非逃逸)会有 Warnning 提示,而且我们说过一般这种情况下 Apple 的工程师都会在 LLVM 为 Objective-C 加一个宏来迎合 Swift…
1 | // Warning for Missing Noescape Annotations for Method Overrides @interface DispatchExecutor : NSObject<Executor> - (void)performOperation:(NS_NOESCAPE void (^)(void))handler; @end @implementation DispatchExecutor - (void)performOperation:(NS_NOESCAPE void (^)(void))handler { } |
个人观点
如果 Swift 5 真的可以做到 ABI 稳定,那么 Swift 与 Objective-C 混编的 App 包大小也应该回归正常,相信很多公司的项目都会慢慢从 Objective-C 转向 Swift。在 Swift 中闭包(Closures)作为一等公民的存在奠定了 Swift 作为函数式语言的根基,本次 LLVM 提供了将 Swift 中的 Closures 与 Objective-C 中的 Block 互通转换的支持无疑是很有必要的。
使用 #pragma pack 打包 Struct 成员
Emmmmm… 老实说这一节的内容更底层,所以可能会比较晦涩,希望自己可以表述清楚吧。在 C 语言中 struct 有 内存布局(memory layout) 的概念,C 语言允许编译器为每个基本类型指定一些对齐方式,通常情况下是以类型的大小为标准对齐,但是它是特定于实现的。
嘛~ 还是举个例子吧,就拿 WWDC18 官方演示文稿中的吧:
1 | struct Struct { |
在上述例子中,编译器为了对齐内存布局不得不在 Struct 的第二字段与第三字段之间插入 2 个 byte。
1 | | 1 | 2 | 3 | 4 | |
这样本该占用 6 byte 的 struct 就占用了 8 byte,尽管其中只有 6 byte 的数据。
C 语言允许每个远程现代编译器实现 #pragma pack,它允许程序猿对填充进行控制来依从 ABI。
From C99 §6.7.2.1:
12 Each non-bit-field member of a structure or union object is aligned in an implementation- defined manner appropriate to its type.
13 Within a structure object, the non-bit-field members and the units in which bit-fields reside have addresses that increase in the order in which they are declared. A pointer to a structure object, suitably converted, points to its initial member (or if that member is a bit-field, then to the unit in which it resides), and vice versa. There may be unnamed padding within a structure object, but not at its beginning.
实际上关于 #pragma pack 的相关信息可以在 MSDN page 中找到。
LLVM 本次也加入了对 #pragma pack 的支持,使用方式如下:
1 |
|
经过 #pragma pack 之后我们的 struct 对齐方式如下:
1 | | 1 | |
其实 #pragma pack (push, 1) 中的 1 就是对齐字节数,如果设置为 4 那么对齐方式又会变回到最初的状态:
1 | | 1 | 2 | 3 | 4 | |
值得一提的是,如果你使用了 #pragma pack (push, n) 之后忘记写 #pragma pack (pop) 的话,Xcode 10 会抛出 warning:

个人观点
嘛~ 当在网络层面传输 struct 时,通过 #pragma pack 自定义内存布局的对齐方式可以为用户节约更多流量。
Clang 静态分析
Xcode 一直都提供静态分析器(Static Analyzer),使用 Clang Static Analyzer 可以帮助我们找出边界情况以及难以发觉的 Bug。
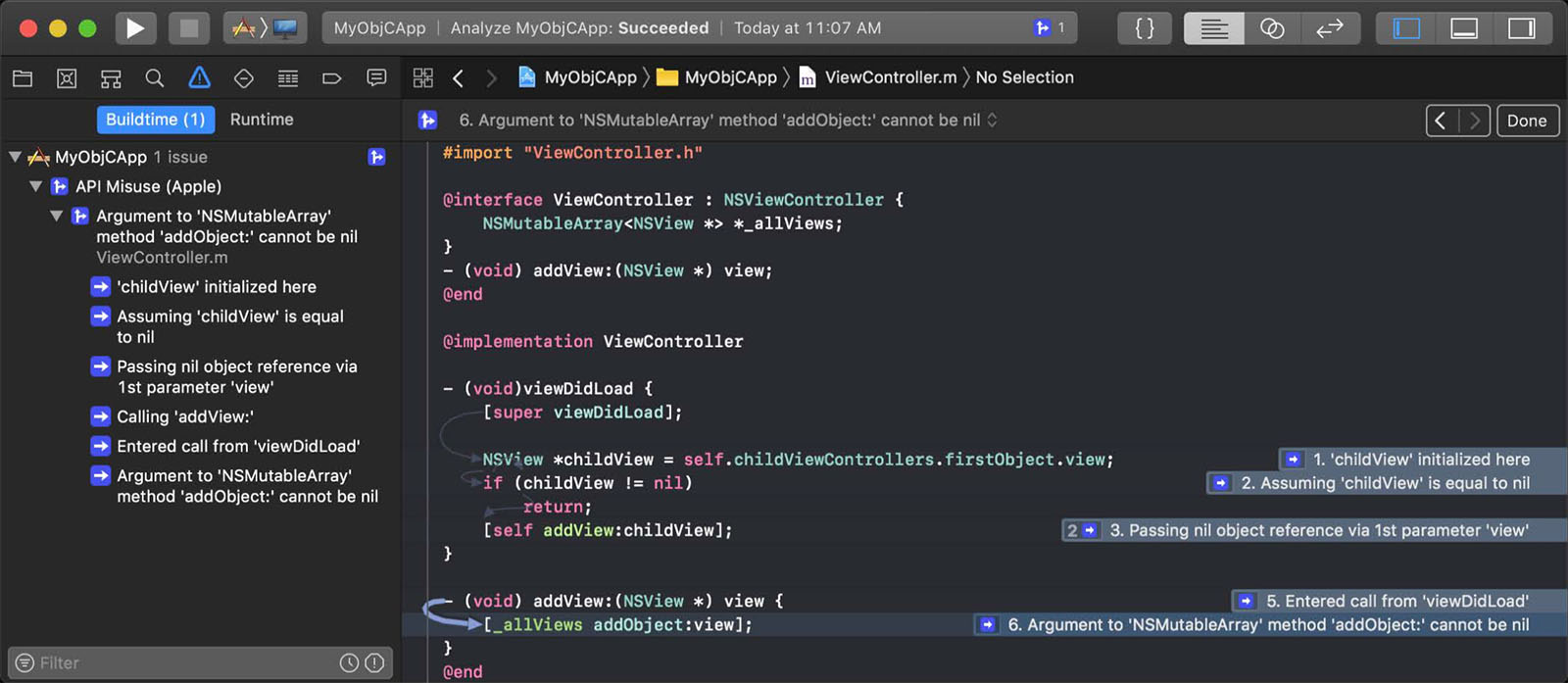
点击 Product -> Analyze 或者使用快捷键 Shift+Command+B 就可以静态分析当前构建的项目了,当然也可以在项目的 Build Settings 中设置构建项目时自动执行静态分析(个人不推荐):
本地静态分析器有以下提升:
- GCD 性能反模式
- 自动释放变量超出自动释放池
- 性能和可视化报告的提升
GCD 性能反模式
在之前某些迫不得已的情况下,我们可能需要使用 GCD 信号(dispatch_semaphore_t)来阻塞某些异步操作,并将阻塞后得到的最终的结果同步返回:
1 | __block NSString *taskName = nil; |
嘛~ 这样写有什么问题呢?
上述代码存在通过使用异步线程执行任务来阻塞当前线程,而 Task 队列通常优先级较低,所以会导致优先级反转。
那么 Xcode 10 之后我们应该怎么写呢?
1 | __block NSString *taskName = nil; |
如果可能的话,尽量使用 synchronous 版本的 API。或者,使用 asynchronous 方式的 API:
1 | [self.connection.remoteObjectProxy requestCurrentTaskName:^(NSString *task) { |
可以在 build settings 下启用 GCD 性能反模式的静态分析检查:

自动释放变量超出自动释放池
众所周知,使用 __autoreleasing 修饰符修饰的变量会在自动释放池离开时被释放(release):
1 | @autoreleasepool { |
这种看似不需要我们注意的点往往就是引起程序 Crash 的隐患:
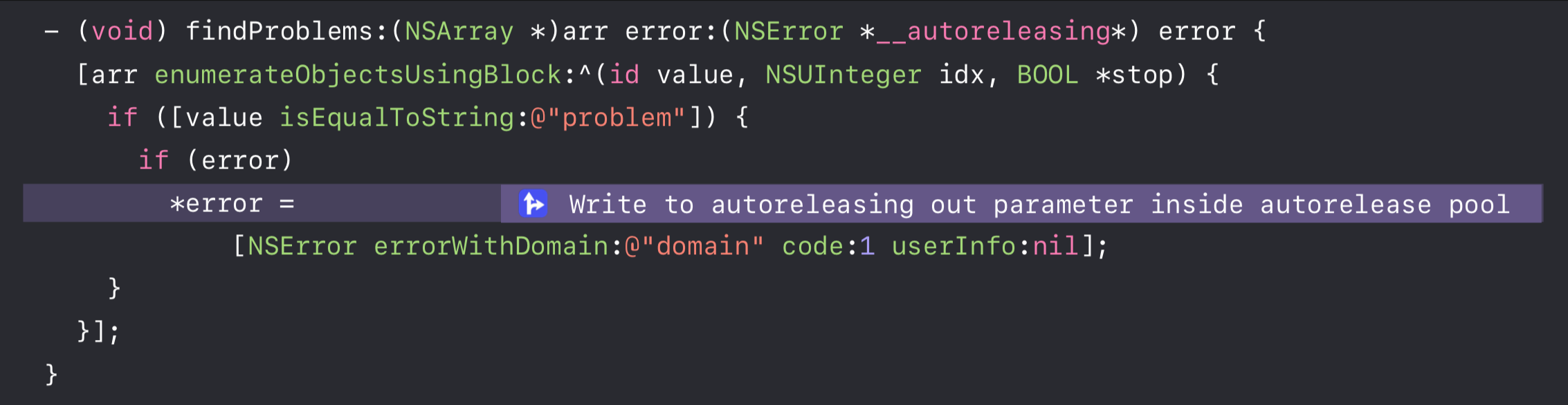
1 | - (void)findProblems:(NSArray *)arr error:(NSError **)error { |
嘛~ 上述代码是会引起 Crash 的,你可以指出为什么吗?
Objective-C 在 ARC(Automatic Reference Counting)下会隐式使用 __autoreleasing 修饰 error,即 NSError *__autoreleasing*。而 -enumerateObjectsUsingBlock: 内部会在迭代 block 时使用 @autoreleasepool,在迭代逻辑中这样做有助于减少内存峰值。
于是 *error 在 -enumerateObjectsUsingBlock: 中被提前 release 掉了,这样在随后读取 *error 时会出现 crash。
Xcode 10 中会给出具有针对性的静态分析警告:
正确的书写方式应该是这样的:
1 | - (void)findProblems:(NSArray *)arr error:(NSError *__autoreleasing*)error { |
Note: 其实早在去年的 WWDC17 Session 411 What’s New in LLVM 中 Xcode 9 就引入了一个需要显示书写
__autoreleasing的警告。
性能和可视化报告的提升
Xcode 10 中静态分析器可以以更高效的方式工作,在相同的分析时间内平均可以发现比之前增加 15% 的 Bug 数量。
不仅仅是性能的提升,Xcode 10 在报告的可视化方面也有所进步。在 Xcode 9 的静态分析器报告页面有着非必要且冗长的 Error Path:
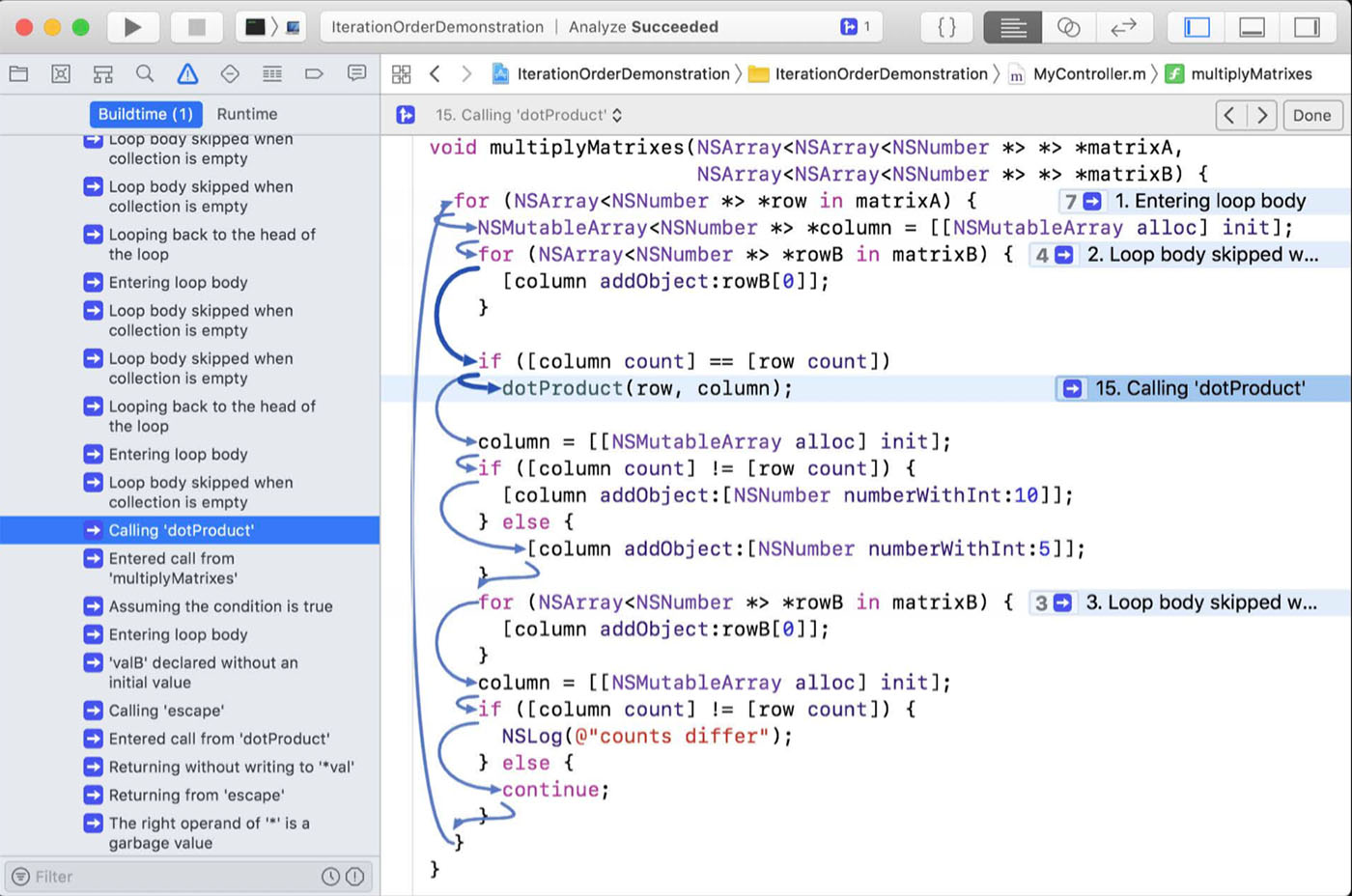
Xcode 10 中则对其进行了优化:
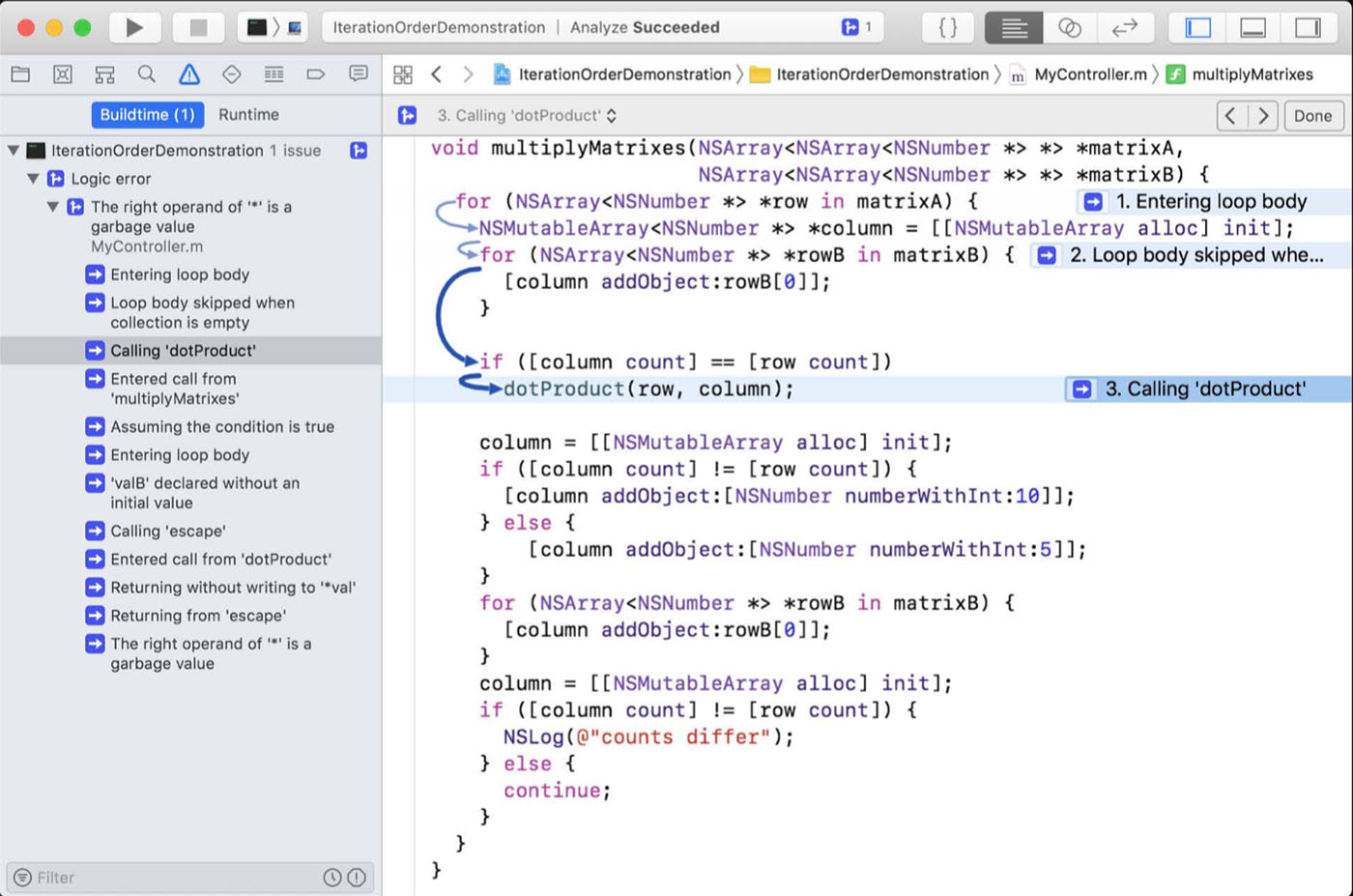
个人观点
嘛~ 对于 Xcode 的静态分析,个人认为还是聊胜于无的。不过不建议每次构建项目时都去做静态分析,这样大大增加了构建项目的成本。
个人建议在开发流程中自测完毕提交代码给组内小伙伴们 Code Review 之前做静态分析,可以避免一些 issue 的出现,也可以发现一些代码隐患。有些问题是可以使用静态分析器在提交代码之前就暴露出来的,没必要消耗组内 Code Review 的宝贵人力资源。
还可以在 CI 设置每隔固定是时间间隔去跑一次静态分析,生成报表发到组内小群,根据问题指派责任人去检查是否需要修复(静态分析在比较复杂的代码结构下并不一定准确),这样定期维护从某种角度讲可以保持项目代码的健康状况。
增加安全性
Stack Protector
Apple 工程师在介绍 Stack Protector 之前很贴心的带领着在场的开发者们复习了一遍栈 Stack 相关的基础知识:

如上图,其实就是简单的讲了一下 Stack 的工作方式,如栈帧结构以及函数调用时栈的展开等。每一级的方法调用,都对应了一张相关的活动记录,也被称为活动帧。函数的调用栈是由一张张帧结构组成的,所以也称之为栈帧。
我们可以看到,栈帧中包含着 Return Address,也就是当前活动记录执行结束后要返回的地址。
那么会有什么安全性问题呢?Apple 工程师接着介绍了通过不正当手段修改栈帧 Return Address 从而实现的一些权限提升。嘛~ 也就是历史悠久的 缓冲区溢出攻击。

当使用 C 语言中一些不太安全的函数时(比如上图的 strcpy()),就有可能造成缓冲区溢出。
Note:
strcpy()函数将源字符串复制到指定缓冲区中。但是丫没有指定要复制字符的具体数目!如果源字符串碰巧来自用户输入,且没有专门限制其大小,则有可能会造成缓冲区溢出!
针对缓冲区溢出攻击,LLVM 引入了一块额外的区域(下图绿色区域)来作为栈帧 Return Address 的护城河,叫做 Stack Canary,已默认启用:
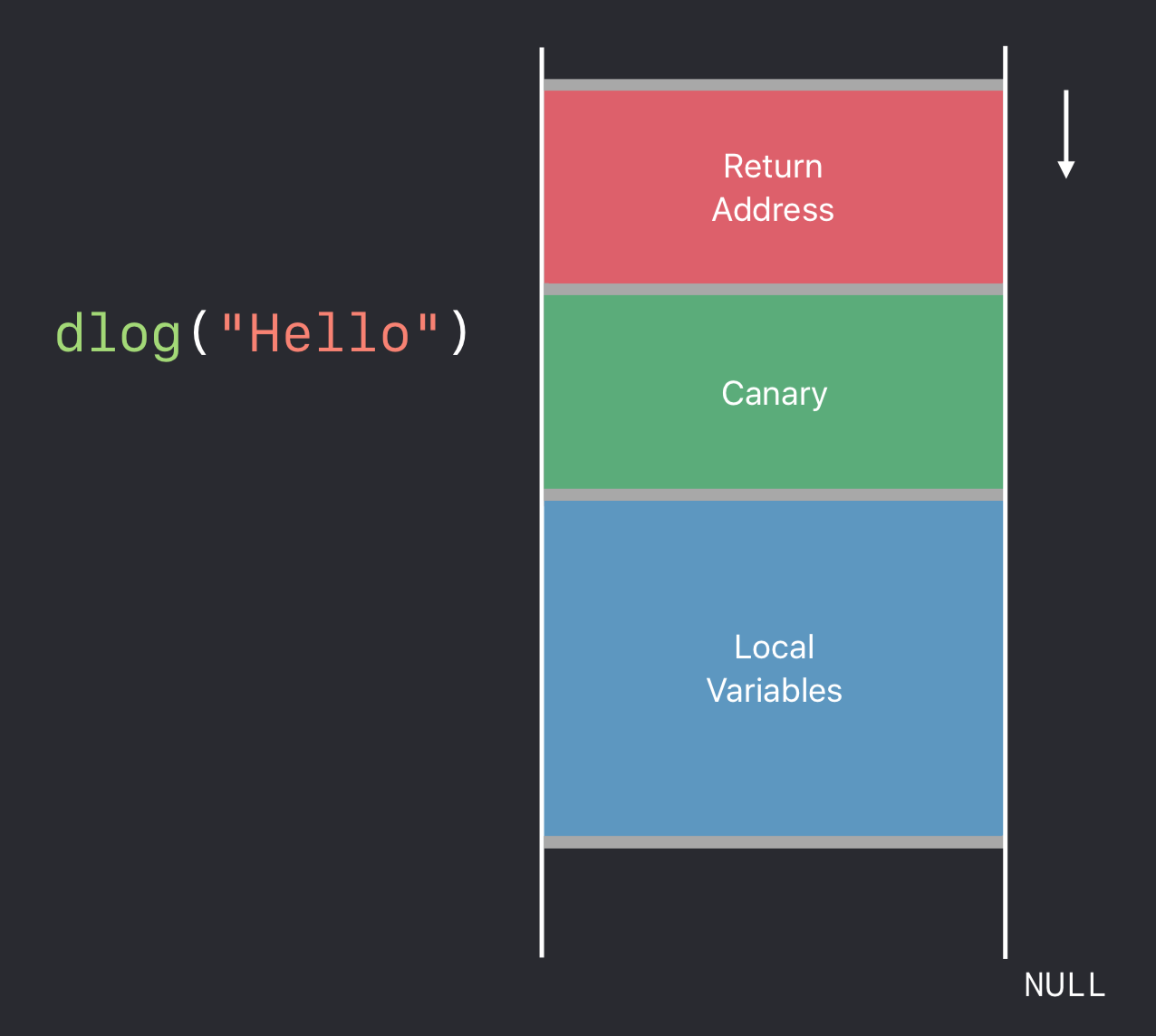
Note: Canary 译为 “金丝雀”,Stack Canary 的命名源于早期煤矿工人下矿坑时会携带金丝雀来检测矿坑内一氧化碳是否达到危险值,从而判断是否需要逃生。
根据我们上面对缓冲区溢出攻击的原理分析,大家应该很容易发现 Stack Canary 的防御原理,即缓冲区溢出攻击旨在利用缓冲区溢出来篡改栈帧的 Return Address,加入了 Stack Canary 之后想要篡改 Return Address 就必然会经过 Stack Canary,在当前栈帧执行结束后要使用 Return Address 回溯时先检测 Stack Canary 是否有变动,如果有就调用 abort() 强制退出。
嘛~ 是不是和矿坑中的金丝雀很像呢?
不过 Stack Canary 存在一些局限性:
- 可以在缓冲区溢出攻击时计算 Canary 的区域并伪装 Canary 区域的值,使得 Return Address 被篡改的同时 Canary 区域内容无变化,绕过检测。
- 再粗暴一点的话,可以通过双重
strcpy()覆写任意不受内存保护的数据,通过构建合适的溢出字符串,可以达到修改 ELF(Executable and Linking Format)映射的 GOT(Global Offset Table),只要修改了 GOT 中的_exit()入口,即便 Canary 检测到了篡改,函数返回前调用abort()退出还是会走已经被篡改了的_exit()。
Stack Checking
Stack Protector 是 Xcode 既有的、且默认开启的特性,而 Stack Checking 是 Xcode 10 引入的新特性,主要针对的是 Stack Clash 问题。
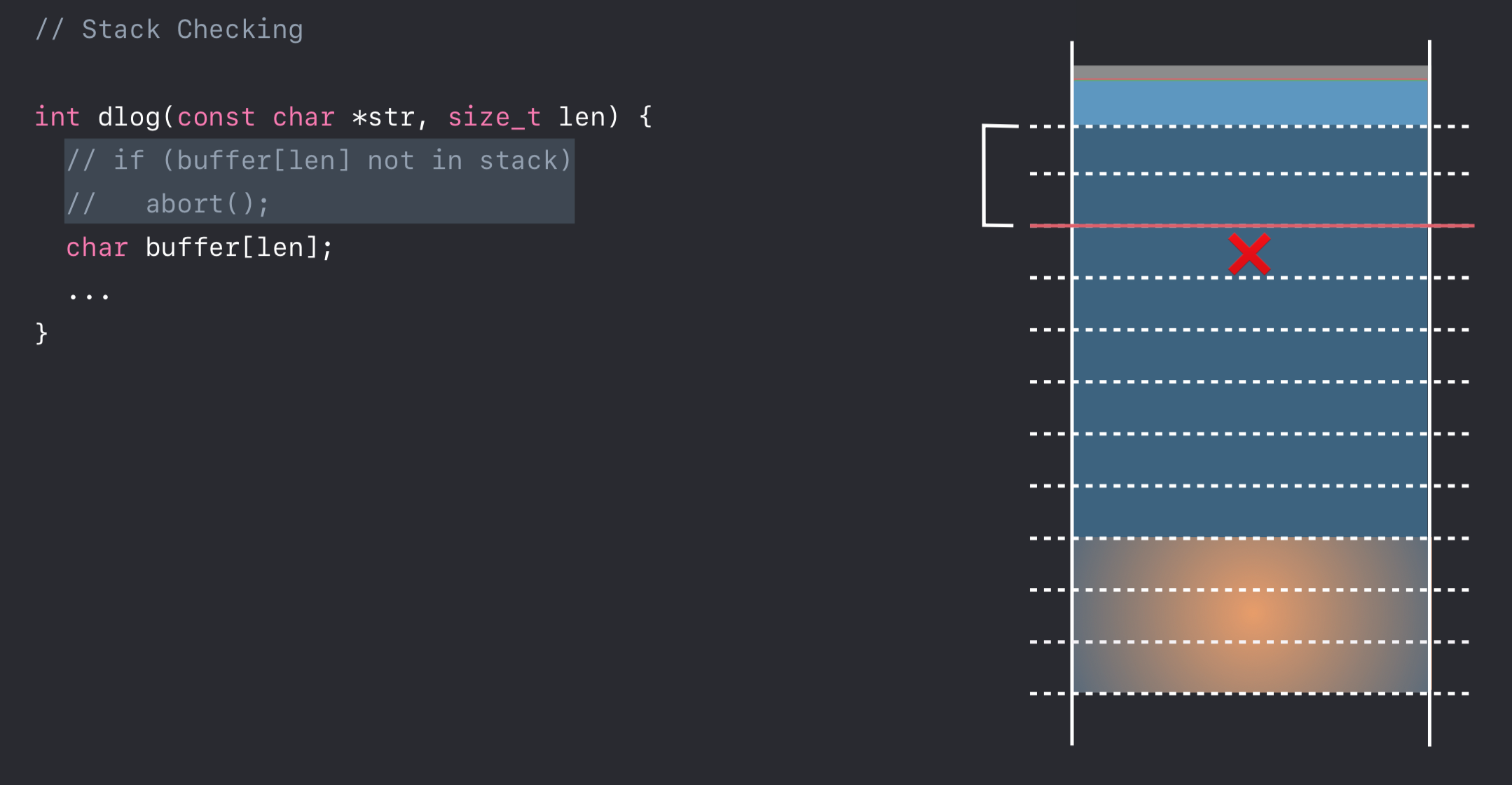
Stack Clash 问题的产生源于 Stack 和 Heap,Stack 是从上向下增长的,Heap 则是自下而上增长的,两者相向扩展而内存又是有限的。
Stack Checking 的工作原理是在 Stack 区域规定合理的分界线(上图红线),在可变长度缓冲区的函数内部对将要分配的缓冲区大小做校验,如果缓冲区超出分界线则调用 abort() 强制退出。
Note: LLVM 团队在本次 WWDC18 加入 Stack Checking,大概率是因为去年年中 Qualys 公布的一份 关于 Stack Clash 的报告。
新指令集扩展

Emmmmm… 这一节的内容是针对于 iMac Pro 以及 iPhone X 使用的 指令集架构(ISA - Instruction set architecture) 所做的扩展。坦白说,我对这块并不是很感兴趣,也没有深入的研究,所以就不献丑了…
总结
本文梳理了 WWDC18 Session 409 What’s New in LLVM 中的内容,并分享了我个人对这些内容的拙见,希望能够对各位因为种种原因还没有来得及看 WWDC18 Session 409 的同学有所帮助。
文章写得比较用心(是我个人的原创文章,转载请注明 https://lision.me/),如果发现错误会优先在我的个人博客中更新。如果有任何问题欢迎在我的微博 @Lision 联系我~
希望我的文章可以为你带来价值~